

Ever got stuck in a payment gateway processing?
Did you feel your heartbeat getting faster and that you might lose your hard-earned money?
We’ve all been there, mate!
We remember a scene when we were purchasing a phone from Flipkart a couple of years ago. When we did the checkout and went to the payment gateway, it was not responding. Because of this, we had to go to some other e-commerce site (Amazon) to purchase the same. Since that time, it has had a negative impact on my brain regarding the payment gateway on Flipkart!
These situations occur due to the surprising outages that happen!
In the time of traditional data center environments, we have seen several enterprises and businesses facing application outages. These outages can be due to several reasons, such as a power grid down, cable cut, UPS power outage, hardware crash, etc. These outages not only have always cost businesses huge amounts of data but also loads of money.
We’ll take you on this tiny journey of a few minutes and tell you all about how this outage happens, how to follow discovery recovery management, what could be done, and having a better understanding of the topic!

The Real Question is “Why?”
The very basic reason why enterprises have been moving their business-critical applications to the cloud is that the cloud provides a relatively easy and cheap DR setup. Maintaining on-premises infrastructure for cloud DR can be very painful, as it demands high maintenance and setup costs.
As observed recently, cloud technologies have become highly advanced, but shockingly, regardless of such advancements, even the largest public cloud providers, such as AWS and Azure, have been facing outages!
To explain this better, back in December 2021, AWS experienced three back-to-back outages where us-east-1 AZ went down for hours due to a networking issue. This major outage affected many well-known businesses, such as Netflix, Slack, and Amazon.com. Whereas, Microsoft Teams faced major outages in the US and Canada, as it runs on Azure’s cloud, too.
What Actions Are Possible?
Businesses, being the base of this never-stopping world, cannot afford such outages. To ensure business continuity, it is important to set up geographically separated DR sites in another cloud region. Enterprises today have shifted their focus more towards high availability, fault tolerance, disaster recovery in cloud computing and in general, and self-healing.
Understanding The World of Disaster Recovery
Before diving into the technical aspects of cloud DR, let’s try to understand some of the common terminologies related to DR.
Disaster
In terms of cloud computing, a disaster is an event that can cause an unplanned disruption of normal business processes, resulting in the going down of the entire application or its essential parts. This can be due to Application-level failure, a misconfiguration in Hypervisor, a power outage in the cloud data center, etc. For discussion in this particular blog, we will be considering the scenario where the entire cloud region goes down.
Disaster Recovery Region
This refers to the standby region for any application in case a disaster occurs. Geographically, it will be miles apart from the primary region where the application is hosted so that in case of a disaster in the primary region, it does not affect this region.
Moving on, for compliance and lower latency, it is advised that the second region should not be very far from the primary one. Also, for some of the organizations, it is a compliance requirement that their data does not go out of the country, and for them, both regions should be in the same country or continent.
Recovery Time Objective (RTO)
This is the amount of time required for an application to recover from any disaster, and it may vary according to the Service Level Agreement (SLA).This time is utilized to set up and run the DR region from the backups and switch the DNS to the recovery site. The RTO depends on the disaster recovery plan and approaches an organization is opting for (which will be discussed later in this blog).
Recovery Point Objective (RPO)
As per the Service Level Agreement (SLA) RPO is the maximum amount of data that can be lost (in minutes) in case of a disaster. In non-technical terms, it means that whenever an application is restored from a disaster, there should be no reporting of the loss of any committed changes.
Here is an example for better understanding, assuming the last available good copy of data upon an outage is from 18 hours ago and the RPO for this business (SLA) is 20 hours, then we are still within the parameters of the Business Continuity Plan’s RPO.
Importance Of Different Configurations
Talking about applications, each organization has a different set of applications that they host on the cloud, and each application is also likely to have a different SLA depending on the nature and purpose of the application.
Some applications, on the one hand, may not be very demanding and can handle some hours of outages, while others may be mission-critical applications (such as a payment gateway) that, if the application goes down even for a minute, can cost a huge loss of millions of dollars to the organization. Everyone knows how our hearts stop when the scary notification of “payment failed” pops up, right?
Hence, the configuration of disaster recovery should happen differently for each of the classes of applications.
Categories Of Disaster Recovery Setup
When it comes to the cloud, there are four categories of DR setups that are popular and widely accepted across all the cloud providers and can serve most application DR needs:
-
- Backup and Restore
-
- Warm Standby
-
- Pilot Light
-
- Multi-site active-active
Let’s understand the cost vs. resiliency of each of the following through this graphical representation:

Going from top to bottom on the above 4 strategies, it is visible that the lower cost can result in higher RPO and RTO, whereas if we spend more on the DR strategies such as warm standby or active-active standby, the RPO and RTO decrease significantly.
Now, with this said, all we have to figure out is the right option available for the application! While this setup can be practiced across any of the cloud providers, for this blog, we have considered AWS as the cloud provider and tried to provide context.
Backup and Restore
This is the cheapest form of DR strategy available. It can be used for non-production and non-mission-critical applications, which can afford a few hours of downtime and tolerate some data loss.
In this planning, the application components such as app data, DB, console, media files, and documents are backed up on a regular basis in the pre-defined backup window, and a copy of that backup is kept in the DR region. In this way, during a disaster, the application components can be restored using these backups. The actual application footprint is still not there in the DR region, but the organization can keep some landing zone things ready, such as VPC, security configurations, etc.
This is the simplest and lowest-cost solution for DR, but the drawback is that there are high chances of human error. Despite regular DR drills, it has been observed that when an actual disaster occurs, some things can easily be missed. Even though automation can help decrease human error, having a detailed DR runbook is just one way to make it more effective. It also mentions all the necessary steps needed for successfully restoring the application in the secondary region.
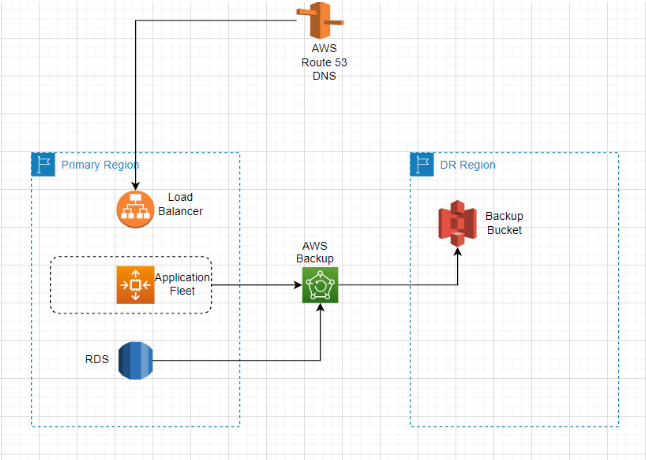
Use Cases:
This strategy is advised to be considered for development environments and low-budget and low-priority applications.
Warm Standby
In the Warm Standby setup, the application stack runs in the primary region, but there is a scaled-down, fully functional copy of the application stack in the DR region. The IaaC tools, such as CloudFormation or Terraform, are used to quickly deploy the infrastructure to scale in case of disaster.
Another part of the automation script is set up to pick the most recent copy of the backup and bring resources up to date. When the DR environment is fully scaled to serve the traffic like the primary environment, it is called hot standby.
In case of a disaster, the automation script is used to provision all resource components and restore applications and databases. DNS records can be manually/automatically updated to point to the newly created application in the DR region.
This is a very common DR setup when the main aim is to achieve a balance between cost and performance. In the case of these saddening outages, applications can suffer up to 15 minutes of the outage, but as the DR site is not active until the disaster, it reduces the customer’s cost. Although, for a small cost cloud-native PaaS applications for databases such as RDS/ DynamoDB, have the capability of syncing data across the region in real-time.
The cost of setting up Warm Standby is slightly higher than the Backup and Restore method, along with more effort being required in the setting up of automation scripts and testing them. Frequent DR drills must be performed to ensure the scrips and automation are working properly in case of a disaster. Annual or half-yearly DR drills are some of the practices that organizations perform to ensure the success of DR.

Use Cases:
This DR strategy is used for applications with high priority but not mission-critical applications. These are the types of applications where the data does not include banking transactions.
Pilot Light
The word “pilot light” itself refers to the lighting system in the house where a small burner is always kept lit, which is used to ignite the larger burner when needed. This concept keeps the setup warm and avoids any end-to-end hassle; this is just the Pilot Light setup in simpler terms.
In the Pilot Light setup, the entire application fleet runs in the primary region as usual, and a small portion of the applications, i.e., small-size EC2 instances, RDS databases, etc., are running in the DR region. Since the application on the secondary site is always running, along with the backup, live data sync is always happening between the primary and DR regions.
In case of a disaster, the DR infrastructure is scaled up to its full capacity to match the primary site, and DNS rerouting is done to send traffic to the DR region.
This setup has an advanced level of availability, because, unlike Warm Standby, the infrastructure is always running at the DR site. The only difference is that it is scaled to its full capacity in case of disaster. Since the application is always running on the DR site, this setup provides the advantage of testing the DR site from time to time, but at the same time, it also incurs some extra cost as the smaller version of infrastructure always needs to run on a secondary site.

Use Cases:
High-priority applications that require frequent modifications.
Multi-Site Active-Active
This is the kind of DR practice that is required for mission-critical and high-priority applications. In this setup, the application is deployed on multiple sites, and it actively serves traffic from multiple regions. It does require live synchronization of data across multiple sites and is one of the most costly and complex DR strategies, but at the same time, it can also reduce the recovery time to almost zero! Amazing, isn’t it?
In case of a disaster at the primary site, the Route53 routing policy automatically detects the failure of the primary site, and the new user requests failover to the DR region. Developers need to ensure that the changes are coming through automation scripts and updating both sides of the infrastructure. If designed properly, this DR setup can avoid major regional outages without any human intervention at all.

Use Cases:
Mission-critical applications with the highest priority and availability, such as payment gateways, order delivery systems, banking systems, etc.
Conclusion
With all the available DR options being discussed above, it is now upon the enterprise and the business owners to decide the approach in terms of RPO, RTO, the criticality of the application, and the budget allocated for the DR solution. It is then up to the architects who will have to design the DR solution in terms of requirements. The solution can be a single DR approach, as discussed above, or it can be a hybrid model which combines two or more.
Proper strategy, implementation, testing, and maintenance can help the application outage and reduce millions of dollars in business losses. Moreover, the downtime of the application can lead to unhappy customers who may never even revisit the application if they face any outages!
To avoid such outage-affected kinds of embarrassing situations for end-users and customers, it is very important to have a DR solution ready that will not only save millions for the business but will also prevent the customer from inconveniences.
And that is all for this blog post. Keep reading more such blogs or seek practical help, including disaster recovery strategies, only at CloudZenia.

Leave a Reply